
One Request, One AI Call
A simple pattern to follow that has clear benefits for any AI-driven program


It’s easy to think of an AI as an expert inside a machine. A robot who knows every detail of the difficult tasks we’re looking to solve. And, since it’s basically a program, we can ask without needing to go through the social small talk required with a real life expert. This “machine expert” can be a good analogy, but things get tricky when we start to build software products that use AI LLMs.
While just chatting, I usually ask one question at a time. I’m looking to explore what this expert knows. Their answers give me confidence that the AI understands the question that we’re looking to solve. Once I’m satisfied, I’ll start to craft a solution combining all the knowledge I’ve learned the expert has into a solution. Often several questions are merged into a single AI prompt/query given to the LLM.
These combined prompts might look something like this:
Act like an expert on personal productivity with specifically strong expertise around the Pomodoro technique based on the book {bookName}.
Based on the contents of the book can you give me:
1. a quote that references the Pomodoro Technique
2. two key facts that are interesting to note about the technique
3. a summary of the bookWhen asking about a number of different books, the AI has been able to chat with me and give fairly accurate answers. And, now combined, these questions makes a nice organized program to give me details about the Pomodoro Technique sourcing from any book we give it. Pretty neat!
However, this has process one annoying flaw. As we look at the output, it starts to be strangely coincidental that the summary always seems to be related to the quote and the facts that are referenced. We may even note that the AI expert made up one of the facts, AND that fact has leaked into our summary! That fact didn’t exist in the book at all but the expert seems confident enough to include it in both results.
To understand what’s happening here, let’s do a quick review of how AI LLMs think:

The “AI Brain” has a context (memory) that contains the prompt (setup) and the questions that we gave it. This helps the AI predict what the output should be. The AI does this by constructing parts of words that seem most likely to come next in a sequence. These product the outputs (or in our example, answers).
Now, this is a fine mental model, but what it doesn’t show is that the answers given are also included in the context as they are written! An “answer-context” for our purposes here. So while the AI is trying to reply to the question
2. two key facts that are interesting to note about the technique
it’s also referencing the answer it gave to the first question
1. a quote that references the Pomodoro Technique
You can see this represented here:
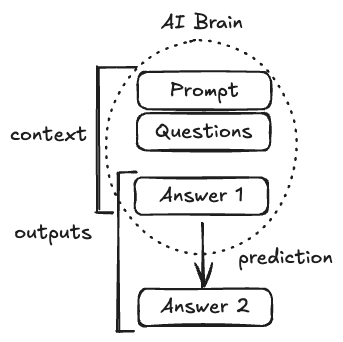
This is completely unexpected. We want the answers to all come out in the same way as before when we were just chatting. The AI should be able to output the same answers it gave us earlier! Unfortunately, that isn’t the case, and this is where the machine expert analogy starts to get in our way. It’s neither a classical machine program, nor an experienced expert.
AI don’t behave in a structured manner and are “creative” to some degree that actually seems to help them come up with more helpful answers than traditional programs in many domains. They’re constantly looking to take advantage of context to better inform their output. It just so happens, answers are part of that context and generally a great place to source information from. Just maybe not for our case.
While we’re trying to give the AI clear instructions, we also need to evaluate how it’ll interpret answers as each answer also becomes part of their programming. It’s strange to think of an expert acting that way… Imagine if you were on a call with your doctor and because he mentioned something about tennis earlier, he’s suddenly convinced that you might have tennis elbow.
Now, this “recency bias” isn’t always a bad thing, we can also use this answer-context to better inform our outputs too. Say we want to understand how relevant a quote is, we could instruct the AI with a prompt like this:
Act like an expert on personal productivity with specifically strong expertise around the Pomodoro technique based on the book {bookName}.
Based on the contents of the book can you give me a list of quotes that are in the book related to the technique. After each quote, tell me how confident you are that the Pomodoro Technique is directly related to the quote by giving me a confidence rating from 0-100%This kind of prompt will have the AI return each quote followed by a rating of how confident it is in the choice of quote. This is a great way to use the answer-context because it allows the LLM to evaluate the output it just gave us and verify how confident it is in the result.
However, order those questions in the opposite order (ex. “give me a confidence rating and then the quote”) and the confidence rating stops meaning what we think it means. Instead, the prompt simply tries to be confident when giving the answer that follows the rating, which isn’t quite the same thing we were hoping to achieve.
I’ve been able to apply this technique of applying a confidence rating successfully to filter out bogus answers and generally arrive at more stable AI solutions. It does require a steerable model, and you may find some models more or less capable of creating these measures in their output. GPT-4 has been the most consistent at creating accurate answers in my testing.
As you can tell, prompt order is kind of a big deal when asking for multiple things. It’s something we’re not geared to watch out for when programming or speaking which makes it easy to overlook when trying to make a quick change. And this is where prompts can often get brittle, too.
Say that later, after some time has passed, I come back to make some changes to the prompt. I make a couple changes to generate a bit more data and happen to re-order the questions being asked. This simple change can completely change the accuracy and quality of the output. Everything being the same, this order change can result in a dramatic shift.
This leads to my practice of making “One Request, One AI Call”. Try not to mix contexts where possible, and request separately for each question that we’re looking to ask. Then later combine the results back into the list answers we were hoping to receive.

This one simple change allows each answer to be performed optimally, and the LLM can focus on the specific task that helps to arrive at each answer. This simplifies how many things are happening, improves accuracy, and can even allow us to downscale the size of the model we need to use for some answers.
But AI calls don’t come cheap. But they do when we can cache the responses we get back from an AI service. Context caching is one of my favourite features that has been rolled out by AI companies in the recent months. It allows us to store the context that the AI knows about so that when another call uses that same context, we can leverage the cache that we already have.

Both OpenAI and Anthropic have solutions available for context caching and it’s turned on by default on many OpenAI models. When making a request using an existing cache, we’ll save around 50% on the subsequent calls. This is a great tradeoff which allows us to get back some of the cost of making so many calls.
Next time you’re debugging your AI solution, try to take a look at how you’re setting up each part of your system. I’ve seen a lot of different teams get stuck on these parts in my time at Hint Services and it’s an easy spot to overlook. As we continue to find these issues it’s become easier to find where we can help and advise companies on better paths of action.
It remains unclear how this applies to thinking-class models like o1. Because a lot of the thinking happens under the hood, it’s difficult to really engineer solutions using their approaches. These tools create their own order of operations as they think through steps internally. At this point it may be safe to assume that there is a bit of logic around this kind of recency-bias that is baked into the step creations of those models. As things develop, we’ll be sure to update you.
Other Ways to Support Stable Discussion
If you’re interested, there are a number of companies that have made us affiliate members. We love these tools and are lucky enough to get a bit of a kickback if our users download them. Try them out and let us know what you think:
Wispr Flow 🎤 - easy voice to text app
Eleven Labs 🗣️ - excellent AI voice creations
Descript 🎬 - amazing AI video editing platform we use for our Youtube
Warp 🌀 - great replacement terminal
I’ll make use of this. Thanks.